用 Maxima 进行符号计算
相比 Matlab, 自由的数学软件 Octave 的另一个弱势是它不能进行符号计算. 我于是寻找开源的符号计算系统, 找到了 Maxima. 下面是官方网站的介绍(翻译)
Maxima 是一个符号和数值计算系统, 它可以进行微分, 积分, 泰勒级数, 拉普拉斯变换, 常微分方程, 线性方程组, 多项式, 集合,列表, 向量, 矩阵, 张量的各种计算. Maxima 利用精确的分数, 任意精度的整数, 和可变长度的浮点数来产生高精度的数值结果.Maxima 可以对函数和数据进行二维和三维绘图.
看上去和 Octave 的很多功能是有重叠的, 不过我只想试试它的符号计算功能. 我找出大一的教材《数学分析简明教程》第二版 上册(邓东皋 尹小玲 编著), 不定积分的习题, 让我小小惊讶的是, Maxima 全部轻松搞定. 找个复杂点的例子Page 191, 7(1)
$$\int \frac{dx}{x(1+2\sqrt{x}+\sqrt[3]{x})}$$
在终端输入 maxima 命令, 在 Maxima 提示符下, 输入
(%i4) integrate(1/(x*(1+2*sqrt(x)+x^(1/3))),x);
得到输出
1/6
4 x - 1
1/3 1/6 atan(----------) 1/6
log(x) 3 log(2 x - x + 1) sqrt(7) log(x + 1)
(%o4) 6 (------ - ------------------------ - ---------------- - -------------)
6 8 4 sqrt(7) 4
这是在字符终端哦. 仔细看一下就知道它是什么式子. 很神奇的字符界面哈哈. maxima有一个图形界面工具 wxMaxima, 在wxMaxima 里输入上述命令, 然后 Shift+Enter 得到

非常清晰.
我在想, 大一的时候会这个工具多好啊, 可以用来验证自己的计算是不是正确. 如果想偷懒, 直接抄结果XD
Octave 解线性方程组
$Octave$ 解线性方程组的能力还没有 $matlab$ 强. 对于方程 \(A\times X=B\), $Octave$ 要求 \(A\) 是方阵, \(B\) 是向量; 而 matlab 并没有这些要求, 假设 \(A\) 是 \(m\times n\), \(B\) 是 \(m\times k\), 则可以用 $matlab$ 算出 \(X\), 它是 \(n\times k\) 的.
$Octave$ 解方程组的式子为 \(A\backslash B\). 下面提供两个例子
octave:1> # octave:1> A=[0,2,0,1;2,2,3,2;4,-3,0,1.;6,1,-6,-5] A = 0 2 0 1 2 2 3 2 4 -3 0 1 6 1 -6 -5 octave:2> B=[0;-2;-7;6] B = 0 -2 -7 6 octave:3> A\B ans = -0.50000 1.00000 0.33333 -2.00000
先生成一个随机方阵 $C$ 和随机向量 $D$ 并解方程 $$C\times x=D$$
octave:1> C=rand(5,5) C = 0.847817 0.122730 0.298340 0.652850 0.985631 0.880412 0.618896 0.590534 0.485949 0.763285 0.358464 0.384306 0.469336 0.909417 0.554835 0.306760 0.672447 0.043989 0.371049 0.692044 0.314791 0.410965 0.487560 0.485444 0.892830 octave:2> D=rand(5,1) D = 0.50708 0.99851 0.31515 0.70781 0.66774 octave:3> C\D ans = 0.32657 0.77660 0.32264 -0.50477 0.37354
优秀 c 语言小实例 ---- qsort()
c 语言的标准库有一个函数实现了快速排序----qsort().
man 3 qsort
看看 qsort 函数原型
void qsort(void *base, size_t nmemb, size_t size,
int(*compar)(const void *, const void *));
base 指向要排序的数组. 长度为 nmemb, 每个元素的大小是 size. compar 是比较函数, 如果第一个参数"小于"("等于", "大于")第二个参数, 那么比较函数返回一个负整数(0, 正整数). 数组按升序排序, 改变"小于"的定义就可以按需要的顺序排序了. 下面是 man page 里的一个程序例子, 这个程序将它的参数进行排序
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
static int
cmpstringp(const void *p1, const void *p2)
{
/* The actual arguments to this function are "pointers to
pointers to char", but strcmp(3) arguments are "pointers
to char", hence the following cast plus dereference */
return strcmp(* (char * const *) p1, * (char * const *) p2);
}
int
main(int argc, char *argv[])
{
int j;
if (argc < 2) {
fprintf(stderr, "Usage: %s <string>...\n", argv[0]);
exit(EXIT_FAILURE);
}
qsort(&argv[1], argc - 1, sizeof(argv[1]), cmpstringp);
for (j = 1; j < argc; j++)
puts(argv[j]);
exit(EXIT_SUCCESS);
}
关键句
qsort(&argv[1], argc - 1, sizeof(argv[1]), cmpstringp);
由于 qsort 函数第四个参数类型要求, 不能直接使用 strcmp 函数, 改写的 cmpstringp 函数的类型是:
int(*)(const void *, const void *)
这就符合要求了. qsort 的调用和函数 cmpstringp 的写法有些让人难懂.
我的理解:
&argv[1] 的类型为 char *, 作为实参传给 qsort 函数自动转变为 void * 型指针, 这样在 qsort 函数内部并不知道数组的类型(仅仅知道是void型数组), 因此需要一个参数 size 来标明数组元素的大小.
return strcmp(* (char * const *) p1, * (char * const *) p2);
中的 * (char * const *) p1 应该这么理解: 首先将 p1 转变成 (char * const *) 型指针, 然后在作 * 运算, p1 is a pointer to a const pointer to char. 好费解! *p1 是指向一个 (char * const) 数据, 即 (const char *)数据, 即常字符串. 关于const 的理解可以用"倒读"的方法, 见 const int vs. int const as function parameter in C++ and C 上 Ates Goral 的回答.
qsort 还能怎么用, 看看一个浮点数数组的排序该怎么写, 只需要改变比较函数就可以了
#define eps 0.000001
int numcmp(const void *x,const void *y){ // 排序比较函数
float z=*((double*)x)-*((double*)y);
if(z>eps) return 1;
if(z<-eps) return -1;
return 0;
}
要排序的数组为 price, 如此调用即可:
float price[10] = {32.0, 12, 8, 45.1,
13, 30, 53.2, 34.1, 80, 22}
qsort(price, 10, sizeof(float), numcmp);
换成了 ubuntu 11.10
原先装有 ubuntu 10.04 和 windows 7 双系统. windows 7 几乎没用, 占用空间. ubuntu整个安装在一个逻辑分区上, 分割很不合理, 到现在没有多余的空间可用, 有些空间又动不得. ubuntu 系统感觉越来越丑, 有许多问题, 不想再折腾配置了, 一到重装所有的软件全部没了. 还是早些换掉系统吧.
本想换个 archlinux 或 gentoo 玩玩, 这个安装可能就需要很多时间, 要熟悉它又要很久. 现在 ubuntu (的包管理)都没学好, 换来换去意义不大. 可喜的是, 在寒假装了 LFS, 完全从源代码编译的小系统. 这个用来学习 linux 再好不过了. 当初十分英明的将LFS安装在一个10G的主分区上, 重装系统可以保留它.
这次重装系统, 分区是这样的:
- /boot /dev/sda1 ---100M
- /home /dev/sda2 ---120G
- LFS /dev/sda3 ---10G
- / /dev/sda5 ---40G
- swap ---2.5G
总共用去了100多G, 还剩下120G 可用于扩展.
安装过程相当顺利, 装好重启, 在进入系统时还是出现花屏, 连ubuntu字样都没出现, 有些失望, 之前的系统也出现花屏让我不爽. 试了两次, 换了专有显卡驱动后好多了.
熟悉熟悉Unity 的界面, 便不想换成 awesome 窗口管理器了, 我在 awesome(现在看来比较丑) 上积累的一些经验怕是又浪费了. 给firefox安装了Pentadactyl插件. 遇到了一个问题, 有时 hint-mode 出现问题, 折腾很久才知道是和 ibus 不完全兼容, 没想去 hack 找原因, 还是用小企鹅输入法. 配置好快捷键, 中英文切换切换有问题, 已经设定为shift键, 按了没用, 一阵折腾发现竟要连续摁两次shift键才能切换.
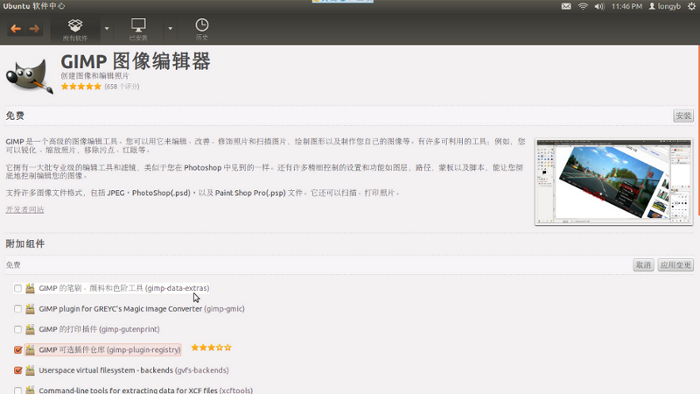
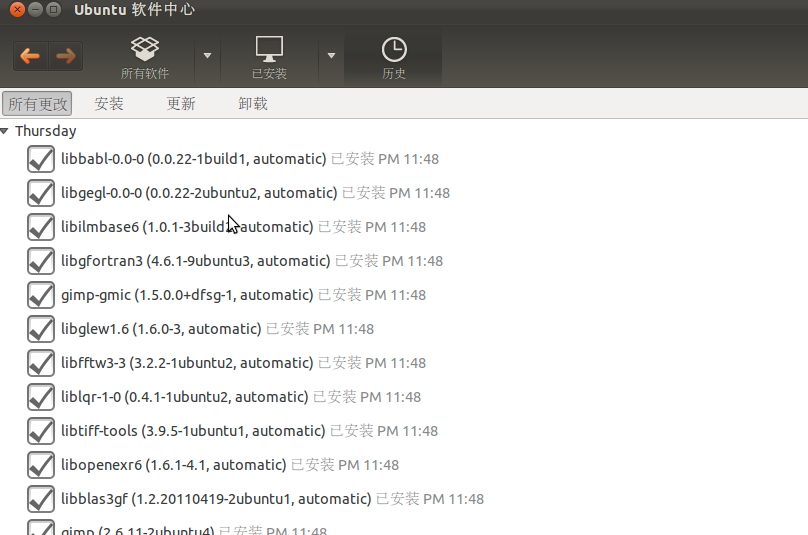
安装好了emacs, vim, zim 等软件. 我发现 ubuntu 11.10 最有趣的是软件中心. 界面相当漂亮, 每个软件有详细的介绍, 一些插件附件可选安装, 还可以评论评分, 另一个很酷的功能是, 它有详细的软件安装卸载的历史记录, 按时间顺序列出, 让你清楚地知道对系统干了什么事.
MIT教授对作业、学习小组及考试的看法
刚看了一小部分MIT公开课“算法导论”第一讲,看来MIT的学生也真“不好过”,教授关于作业、学习小组的看法让我很有感触,比较完满地解答了一直存在自己心头的问题。我觉得这是很值得看的一段视频,也决定把这段讲话抄下来分享,供备忘回味。
---------------------------
Collaboration policy.This is extremely important so everybody pay attention. If you are asleep now wake up. Like that's going to wake anybody up, right?
The goal of homework, Professor Demaine and my philosophy is that the goal of hemework is to help you learn the material. And one way of helping to learn is not to just be stuck and unable to solve something, because then you're in no better shape when the exam roles around, which is where we're actually evaluating you. So, you're encouraged to collaborate.
But there are some commonsense things about collaboration. If you go and you collaborate to the extent that all you're doing is getting the information from somebody else, you're not learning the material and you're not going to do well on the exams. In our experience, students who collaborate generally do better than students who works alone. But you owe it to yourself, if you're going to work in a study group, to be prepared for your study group meeting. And specifically you should spend a half an hour to 45 minutes on each problem before you go to group so you're up to speed and you've tried out your ideas. And you may have solutions to some, you may be stuck on some other ones, but at least you applied yourself to it. After 30 to 45 minutes, if you cannot get the problem, just sitting there and banging your head against it makes no sense. It's not a productive use of your time. And I know most fo you have issues with having time on your hands, right? So, don;t go banging your head against problems that are too hard or where you don't understand what's going on or whatever. That's when the study group can help out. And, as I mentioned, we'll have homework labs which will give you an opportunity to go and do that and coordinate with other students rather than necessarily having to form your own group. And the TAs will be there. If your group is unable to solve the problem, then talk to other groups or ask your recitation instructor. And, that's how you go about solving them.
Writing up the problem sets, however, is your individual responsibility and should be done alone. You don't write up your problem solutions with other students, you write up on your own. And you should on your problem sets, because this is an academic place, we understand that the source of academic information is very important, if you collaborated on solutions you should write a list of the collaborators. Say I worked with so an so on this solution. It does not afect your grade. It's just a question of being scholarly. it is a violation of this policy to submit a problem solution that you cannot orally explain to a member of the course staff. You say oh, well, my wrte-up is similar to that other person's, I didn't copy them. We may ask you to orally explain your solution. If you are unable, according to this policy, the presumptions is that you cheated. So do not write up stuff that you don't understand. You should be able to write up the stuff that you understand. Understand why you're putting down what you're putting down. If it's not obvious, no collaboration whatsoever is permitted in exams...
合作原则:这是非常重要的所以每个人都要注意,如果你在打瞌睡,
课后作业的目的,Demaine教授和我的观点是,
但是有一些关于合作的常识问题,
不过,写作业则是你必须独立完成的过程,这是你的责任。
流密码及RC4算法
大半学期过去,还没交过作业,上上周密码学老师要我们设计一个流密码当作业这周交。俺刚刚学了比较流行的RC4,把自己所学分享出来吧
一、什么是密码系统及流密码?
密码系统(cryptosystem)
私钥密码系统又分为分组密码(block cipher)和流密码(stream cipher)。两者的区别,形象来说,
一次一密的算法非常简单,假设你需要加密的信息(明文)
流密码就是使用较短的一串数字(叫它密钥吧),
在介绍RC4前,说说那个“相加”运算怎么实现。
二、RC4
RC4用两步来生成密码流
首先你指定一个短的密码,储存在key[MAX]数组里,
for i from 0 to 255
S[i] := i
endfor
j := 0
for i from 0 to 255
j := (j + S[i] + key[i mod keylength]) mod 256
swap values of S[i] and S[j]
endfor
第二步利用上面重新排列的数组 S 来产生任意长度的密钥流,算法为
i := 0
j := 0
while GeneratingOutput:
i := (i + 1) mod 256
j := (j + S[i]) mod 256
swap values of S[i] and S[j]
K := S[(S[i] + S[j]) mod 256]
output K
endwhile
output K 一次产生一字符长度(8bit)的密钥流数据,产生密钥流之后,对信息进行加密和解密就只是做个“相加”
附件是我的c代码,编译得到encrypt可执行文件,
我还没研究RC4的安全性,不知道破译密码难度大不大
附件:https://github.com/abellong/simpleRC4Encryption
参考资料:
http://en.wikipedia.org/wiki/
MJB Robshaw - 1995 Stream Ciphers
hello, world
Hi,我是一名本科大三学生(2011),就读于中山大学数学与应用数学专业,大学前基本上没碰过电脑,大一时学了c和c++,仍然对电脑有陌生和恐惧感,当我大二时装上了ubuntu linux之后,慢慢对电脑感兴趣了,而后花很多时间在互联网上,觉得互联网真是太伟大了,由衷的钦佩和感激为丰富互联网内容保持互联网运作而默默贡献的程序员们。分享的理念深入了我的内心,希望自己能做一些有意义的事情,就想建个博客。
我是在ctex论坛上知道这个博客系统,进来之后被它的简洁和理念所吸引,果断开了这个博客(这算是第一个了),想起了一则笑话:一个程序员退休之后决 定 学习书法,买来上好的湖笔、宣纸、墨汁,饱蘸浓墨,在纸上一气呵成:hello, world. 我现在还不是程序员,但希望做个优秀的快乐的程序员哈哈。希望能向大家多多学习:)